XGBoost는 Gradient Boost처럼 예측값과 실제값의 Residual을 계산하고 특정 기준에 따라 decision tree를 만듭니다.
그리고 그 결과를 learning rate를 곱해서 반복적으로 잔차를 개선시키는 방식입니다. 그러나 Gradient Boost와 차이점이 있습니다.
그럼 XGBoost를 Gradient Boost의 차이점을 곁들여 설명하도록 하겠습니다.
1. 초기 예측값(leaf) 초기화
Gradient Boost 알고리즘은 초기 예측값(leaf)를 모든 종속변수의 평균으로 초기화 했습니다.
그러나 XGBoost는 default로 0.5를 사용하고 다양한 값을 넣을 수 있습니다.
2. Residual을 예측하는 Decision Tree를 만듭니다.
이때 Similarity Score를 이용해서 Gain을 구하고 Gain이 가장 큰 것을 기준으로 분기합니다.

이떄 특이한 것이 similarity의 분모에 람다를 더해주는 것인데 이 람다에 따라서 similarity의 값이 점점 작아집니다. 이 특성은 다음에 설명할 regularization과 관련이 있습니다.
3. Similarity,lambda,gamma 값을 이용해서 가지치기(pruning)을 수행합니다.
특정 threshold를 gamma로 정하고 lambda를 적용한 similarity score가 gamma보다 작다면 가지치기를 수행합니다.
이 동작은 분기를 제한하여 Gradient Boost가 가지는 과적합 이슈를 개선시킵니다.
4. 예측값 도출 방법
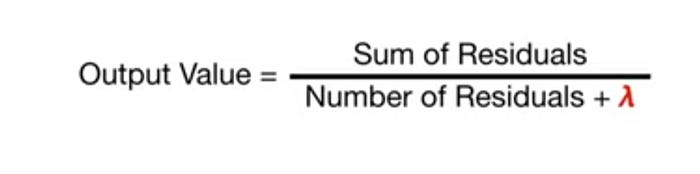
각 트리의 출력값은 위 공식을 통해서 계산합니다. similarity score와 매우 흡사한 모습이지만 잔차의 총합을 제곱하지 않습니다.
초기 예측값에 각 트리의 출력값 * learning rate(eta: default 0.3)을 모두 더하여 최종 예측값을 구합니다.


0 comments:
댓글 쓰기